While architecting distributed cloud applications, you should assume that failures will happen and design your applications for resiliency. A Microservice ecosystem is going to fail at some point or the other and hence you need to learn embracing failures. In short, design your microservices with failure in mind.
Problem Statement
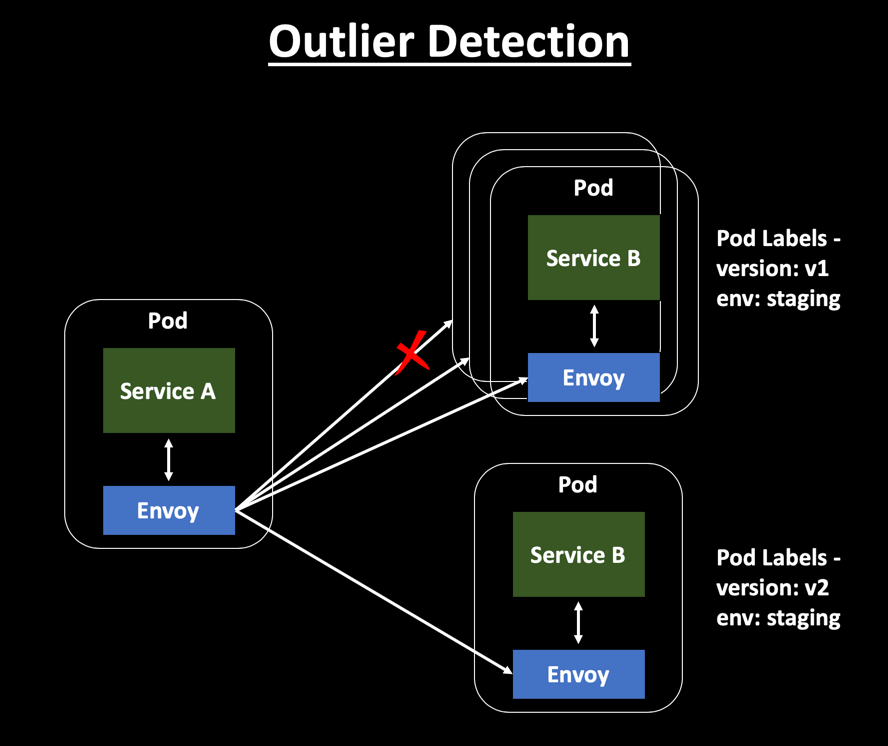
In a K8s environment, services run inside a Pod and dynamically autoscale based on load. To make your services highly available, you might be running multiple instances of your service. But how do you handle scenarios where one of your service instances becomes slow or unresponsive? In such a scenario, you should not send traffic to that instance. But how do you automatically identify this issue at runtime and change your routing rules to exclude this service instance?
Outlier Detection
Outlier Detection is an Istio Resiliency strategy to detect unusual host behavior and evict the unhealthy hosts from the set of load balanced healthy hosts inside a cluster. It automatically tracks the status of each individual host and checks metrics like consecutive errors and latency associated with service calls. If it finds outliers, it will automatically evict them.
Ejection/Eviction implies that the host is identified as unhealthy and won’t be used to cater to user requests as part of the load balancing process. If a request is sent to a service instance and it fails(returns 50X error code), then Istio ejects the instance from the load balanced pool for a specified duration. This is configured as the sleep window.
This entire process increases the overall availability of the services by making sure that only healthy pods participate in catering user requests.
Read more about Envoy Outlier Detection here —
https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/outlier
With the below settings, the dependent service is scanned every 10 sec and if there are any hosts that fail more than 3 times with 5XX error code it will be ejected from the load balanced pool for 20sec.

Read more about Outlier Detection here.
- BaseEjectionTime – The maximum ejection duration for a host. For eg – The host will be ejected for 20sec, before it is evaluated again for processing requests.
- ConsecutiveErrors – Number of errors before a host is ejected from the connection pool. For eg – If you have 3 consecutive errors while interacting with a service, Istio will mark the pod as unhealthy.
- Interval – The time interval for ejection analysis. For eg – The service dependencies are verified every 10sec.
- MaxEjectionPercent – The Max % of hosts that can be ejected from the load balanced pool. For eg – Setting this field as 100 implies that any unhealthy pods throwing consecutive errors can be ejected and the request will be rerouted to the healthy pods.
Outlier Detection will be enabled until the load balancing pool has the minimum number of healthy hosts associated.
While creating a DestinationRule, you can mention the Circuit Breaker fields inside the TrafficPolicy section. Sample DestinationRule below —
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| apiVersion: networking.istio.io/v1alpha3 | |
| kind: DestinationRule | |
| metadata: | |
| name: serviceB | |
| spec: | |
| host: serviceB | |
| subsets: | |
| – labels: | |
| version: v1 | |
| name: serviceB-v1 | |
| trafficPolicy: | |
| connectionPool: | |
| http: {} | |
| tcp: {} | |
| loadBalancer: | |
| simple: RANDOM | |
| outlierDetection: | |
| baseEjectionTime: 20s | |
| consecutiveErrors: 3 | |
| interval: 10s | |
| maxEjectionPercent: 100 | |
| – labels: | |
| version: v2 | |
| name: serviceB-v2 | |
| trafficPolicy: | |
| connectionPool: | |
| http: {} | |
| tcp: {} | |
| loadBalancer: | |
| simple: RANDOM | |
| outlierDetection: | |
| baseEjectionTime: 20s | |
| consecutiveErrors: 3 | |
| interval: 10s | |
| maxEjectionPercent: 100 | |
The below video demonstration from RedHat shows the Istio Outlier Detection functionality in action —
Red Hat Developer Istio Video Series: Number 2 – Istio Pool Ejection
With Outlier Detection – the application is now self-healing wherein if you encounter errors from 1 service instance – you can automatically eject the instance out of the pool such that it doesn’t receive any requests. There is no service downtime with this approach and errors are not thrown to consumers.
Conclusion
Istio improves the reliability and availability of services in the mesh. The basic intent of Outlier Detection is to stop sending requests to the unhealthy instance and give it time to recover. In the meantime, the requests are redirected to the healthy instances such that the consumers are not impacted. The entire implementation of Outlier Detection is transparent to the application and involves no changes to the application code.
Categories: Architecture, Istio, Microservices, Service Mesh
 Smart Pipes and Smart Endpoints with Service Mesh
Smart Pipes and Smart Endpoints with Service Mesh  Visualizing the Istio Service Mesh using Kiali
Visualizing the Istio Service Mesh using Kiali  Chaos Testing your Microservices with Istio
Chaos Testing your Microservices with Istio  Retry Design Pattern with Istio
Retry Design Pattern with Istio 
Samir, Thank you for excellent overview of circuit breaker and need to plan for ‘outages’. Well Done. Thanks, Wilson Hauck http://www.mysqlservertuning.com
LikeLiked by 1 person
As always I appreciate your feedback Wilson. I am working on my upcoming presentation at the O’Reilly Software Architecture Conference, San Jose in a weeks time. Hence I will be blogging about ‘Building a Scalable Microservice Architecture with Istio Service Mesh’ over the next few days.
LikeLike