The Eight Fallacies of Distributed Computing are a set of assumptions that developers make while designing Distributed Systems which might backfire and cause additional work and system redesign in the long run.
In this article, I will briefly discuss each of these fallacies, understand the problem statement and explain the best practices/design patterns that can help us to resolve these issues.

The network is reliable
Service calls made over the network might fail. There can be congestion in network or power failure impacting your systems. The request might reach the destination service but it might fail to send the response back to the primary service. The data might get corrupted or lost during transmission over the wire. While architecting distributed cloud applications, you should assume that these type of network failures will happen and design your applications for resiliency.
To handle this scenario, you should implement automatic retries in your code when such a network error occurs. Say one of your services is not able to establish a connection because of a network issue, you can implement retry logic to automatically re-establish the connection.
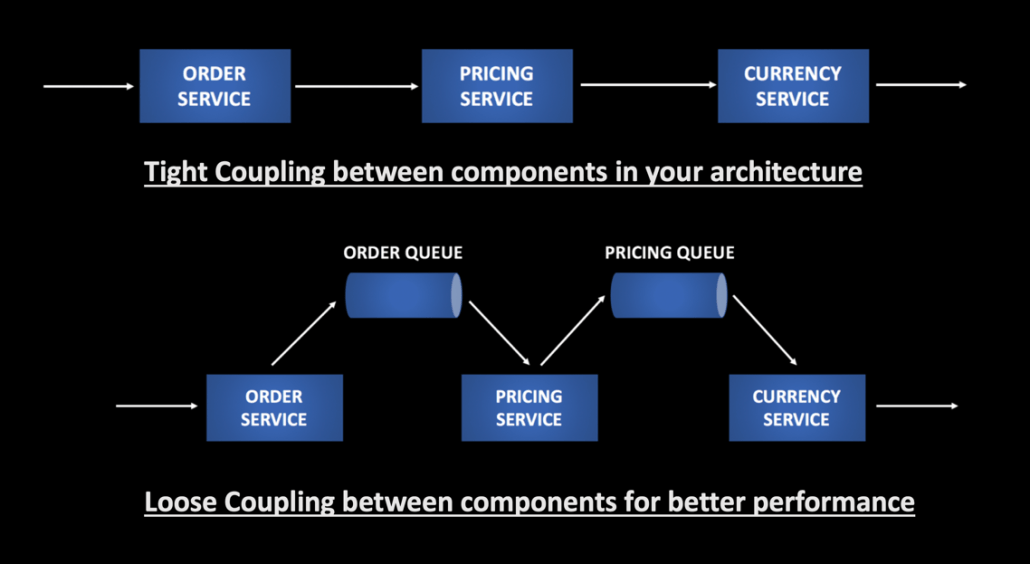
Implementing message queues can also help in decoupling dependencies. Based on your Business use case you can implement queues to make your services more resilient. Messages in the queue won’t be lost until they are processed. If your Business use case allows Fire and Forget type of requests compared to synchronous Request/Response, queues can be a good solution to reduce the tight coupling between components in your architecture and increase system reliability when there are network issues or systems are down.
Latency is zero
Service calls made over the network is not instant. There can be scenarios where you are spending time waiting for the service response. Making remote calls over the internet has much higher latency as compared to making in-memory calls. To add to this pain, if you have services communicating with each other which are hosted in different data centers, there will be a latency associated depending upon the network connectivity, firewalls, available bandwidth, and the data transfer volume.
There are a number of things which you can do to handle such latencies —
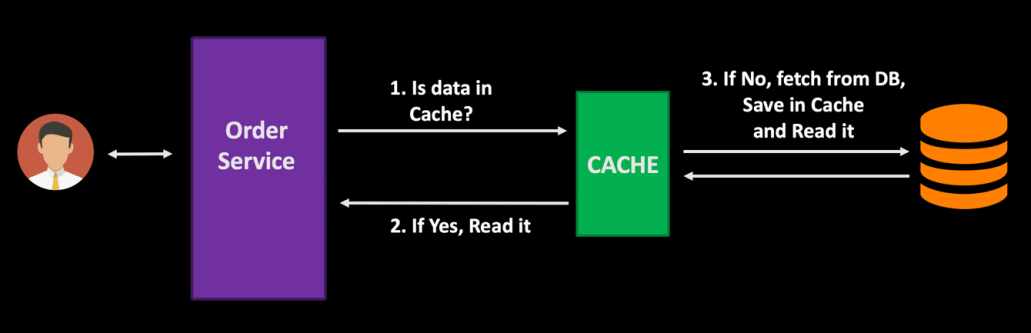
- When you have several dependent services, a well-designed caching strategy can decrease the network cost and improve application performance.
- Try to reduce the number of database calls. Database calls are expensive. The number of roundtrips to the database needs to be minimized.
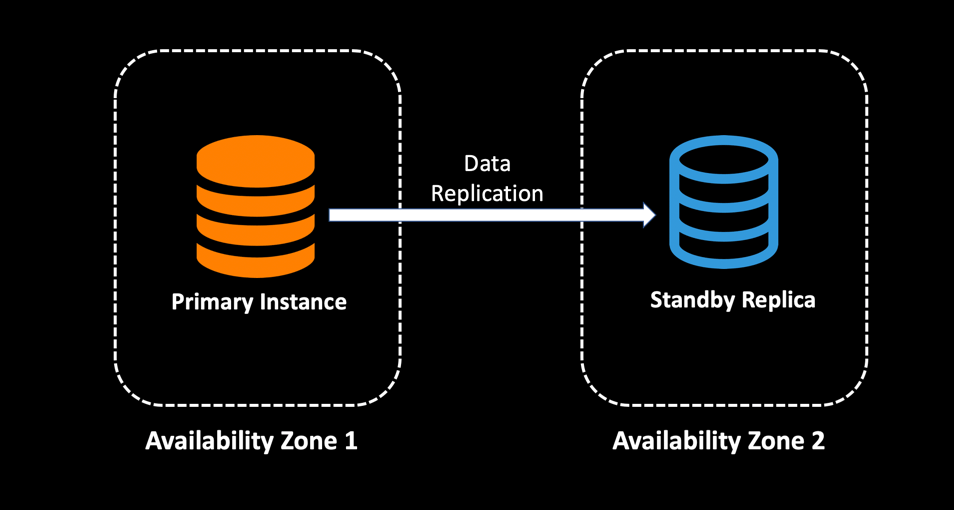
- Implementing technologies like Transaction Replication can help you to move data across Availability Zones with minimal latency.
- If you are leveraging Cloud platforms, then it’s beneficial to deploy applications in Availability Zones near the client location.
- Make bulk requests instead of making hundreds of individual requests from your application.
Bandwidth is infinite
Bandwidth is the capacity of a network to transfer data over a period of time. For an enterprise, as the traffic flowing between the various data centers increases, the requirement for bandwidth increases. It is important to be aware of how much data you need to transfer over the network to suffice your Business use case and the associated dependencies. Depending upon the capacity say 1G vs 10G – the associated cost will change.
When you start working on a new service, you should discuss with Business and figure out what the expected application traffic is going to be and how much data is expected to be flowing over the network & if there is an SLA associated with this data transfer. Things get trickier when you have services communicating with each other and are hosted in different data centers since there is a latency associated with it.
Some potential solutions and approaches to handle such scenario are —
- Applying throttling policy for each of your customers. This will safeguard your system from being overwhelmed by a single customer and in the process impact other customers trying to access your service.
- If you need better network connection you can purchase a dedicated network connection with higher capacity.
- Using database replication technology you can have multiple replicas of your database across different data centers, hence you can manage your application traffic better by splitting it between the replicas.
- In a Monolithic architecture, this issue can get more prominent where we transfer huge amount of data between services. Once you start following Domain Driven Design and break your monolithic application into smaller Microservices you needn’t deal with huge data volume transfer.
The network is secure
There is a fun quote which states that the only network that is secure is the one that is not connected to any network. How many times have we heard in news about security breaches?
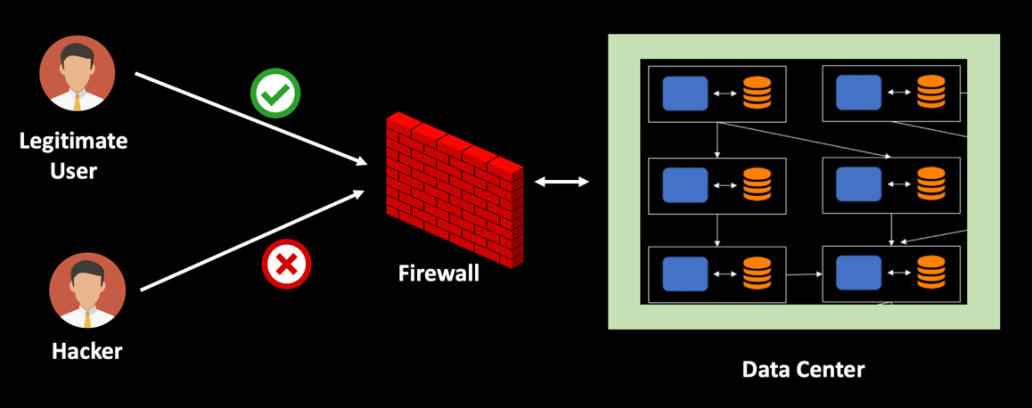
In a distributed system, there can be multiple loopholes in securing your application. Hackers can break through your unsecured network and can cause huge information breach. There can also be a security vulnerability associated with data transmitting over the network. Hence all untrustworthy networks need to be identified.
Building secure applications and having a security mindset is critical to have while developing your applications. Security needs to be built at multiple levels – application, infrastructure, and network.
Some common approaches to secure your network are —
- Firewalls can secure your application infrastructure. It is generally installed between your internal network and the traffic flowing via the Internet. It can secure both incoming and outgoing traffic.
- Implementing Encryption technologies
- Use of certificates
- Authentication mechanisms
Topology doesn’t change
With the rise in Containers and Microservices, environments are no more static. In Cloud Environments, you can implement autoscaling to spin up additional instances of your services as the load increases & scale in when the load decreases.
The ‘Cattle vs Pet‘ analogy is very commonly stated in the container and microservices world. Traditionally the on-premise infrastructure was treated as Pets – they were long-lived and stable. With the advent of Docker containers and cloud technologies, the infrastructure is virtual where service instances are created dynamically based on load. If there is high load, we automatically spin up additional service instances and once the load decreases the instances are terminated.
- From an application development perspective in such dynamic environments, you need to ensure that you are not hardcoding IP and most preferably using hostnames.
- Using Service Discovery tools like Eureka, Consul helps to identify services located in the network so that they can communicate with each other. The logic is very straightforward — There is a central server which maintains the list of service addresses and the clients connects to the central server to retrieve/update these addresses.
There is one administrator
This fallacy reminds me of the ‘Bus Factor‘ which indicates the risk factor if one of the key project members was hit by a bus. However, in a Distributed System involving a number of services, there will be a number of development teams owning the components and most probably an operational team handling the underlying infrastructure including database administration, network firewall configuration, security rules, opening required ports and more.
As organizations start embracing the DevOps culture, there is more collaboration between the development and operations teams. This helps in reducing dependency on a single individual and eliminates the risk of ‘Bus Factor’
Transport cost is zero
There is no such thing called a free lunch. The cost of transporting data across the network is not zero. It requires both time and money. There is a cost associated with transporting data between services — which involves hardware resources, servers, load balancers, switches, routers, infrastructure monitoring, deployment cost – on-premise or cloud.
- When you are developing applications involving the exchange of high data volume, you need to consider the cost of running such a service. Generally, when the data leaves a particular data center there is a cost associated with it.
- You can use standardized protocols like JSON for sharing data between services, as compared to using XML.
The network is homogeneous
A homogenous network can be defined as a network of computers using similar configurations and the same communication protocol. However, this is hard to achieve in the real world. When you are integrating with internal and external services via the network, it is highly probable that the network will be heterogeneous.
From an application perspective, make sure that you make your services resilient and fault tolerant by incorporating design patterns like – Circuit Breaker Pattern, Retry and Timeout Design Pattern.
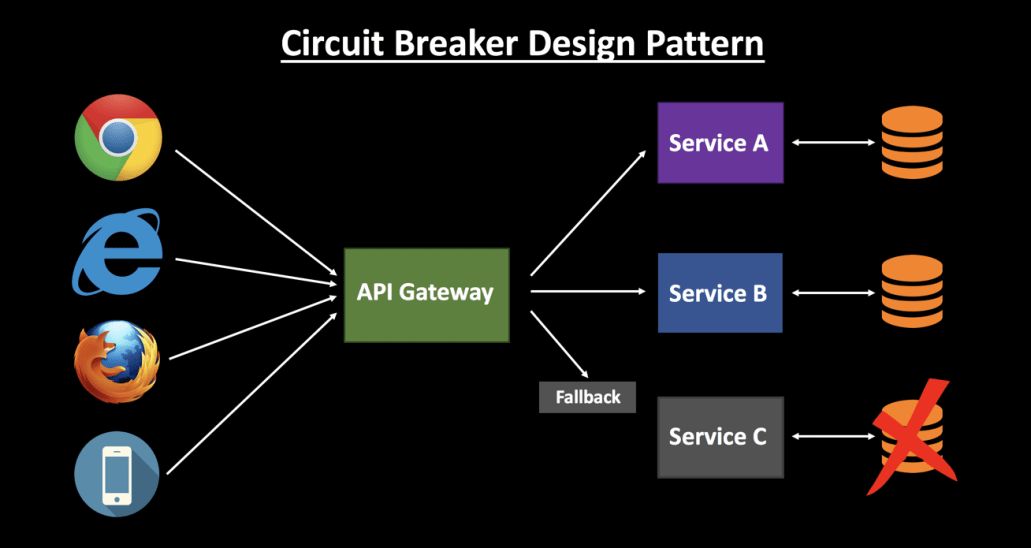
Conclusion –
Designing Distributed Systems is challenging and being aware of these eight fallacies will help you in architecting your systems better.
Additional Resources –
https://www.rgoarchitects.com/Files/fallacies.pdf
Start a 10-day FREE trial at Pluralsight – Over 5,000 courses available
![]()
Categories: Architecture, Microservices
 Smart Pipes and Smart Endpoints with Service Mesh
Smart Pipes and Smart Endpoints with Service Mesh  Visualizing the Istio Service Mesh using Kiali
Visualizing the Istio Service Mesh using Kiali  Chaos Testing your Microservices with Istio
Chaos Testing your Microservices with Istio  Retry Design Pattern with Istio
Retry Design Pattern with Istio 
Samir, Thank you for the reminders, especially resiliency requirements and the ‘retry’ concept.
LikeLiked by 1 person